
9月18日,由中国中文信息学会(CIPS)和中国计算机学会(CCF)共同发起并联合主办的第七届语言与智能高峰论坛召开。论坛上,2022语言与智能技术竞赛赛事组委会为各获奖团队举行了颁奖,赛事各冠军团队就参赛技术方案作详细报告。

语言与智能技术竞赛由中国中文信息学会和中国计算机学会联合主办,百度、中国中文信息学会评测工作委员会和中国计算机学会自然语言处理专委会承办。自2018年举办以来,凭借面向真实应用场景的任务设计和源自真实场景的数据集,该竞赛已成为全球最权威、最热门的中文NLP赛事之一。2022届竞赛进一步升级,联合“千言”数据集开源项目,设置了段落检索、知识对话、情感可解释、视频语义理解四大任务,覆盖了跨模态、知识驱动、可信学习等前沿课题,具有较高的学术和产业价值。
赛题任务的全面升级受到了来自学术界与产业界的广泛关注。据统计,本届竞赛共计约2500支团队报名,参赛选手覆盖全球262所高校和208家企业,提交有效结果超过7000份。其中,高校选手占比约52%,来自清华大学、北京大学、复旦大学、中国人民大学、中国科学院大学、伊利诺伊理工大学、悉尼大学等国内外知名高校;企业选手占比约34%,来自中国移动、联通、平安保险、华为、腾讯、网易、小米、小鹏汽车、海康威视、施耐德电气等知名企业,覆盖了金融、互联网、传媒、通信、工程机械、能源、生物等多个行业。
经过激烈的竞争,最终来自中国科学技术大学、香港中文大学、阿里巴巴、腾讯、商汤科技等高校与企业的共计16支团队获奖。
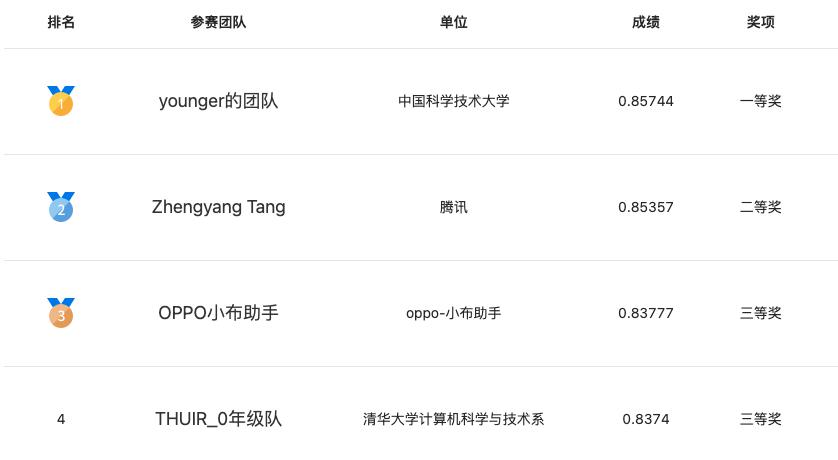

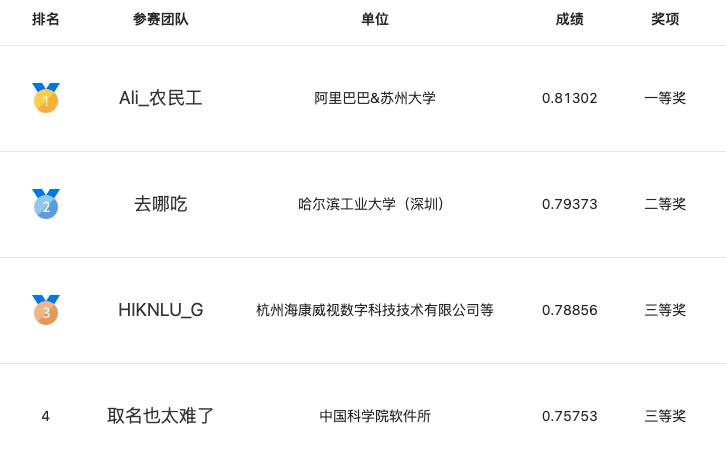

赛事优胜团队在参赛方案中均使用了预训练语言模型,也提出了很多创新思路和方案,并取得了大幅的效果提升。相较于赛事官方的基线成绩,段落检索任务提升了15.40%,知识对话任务提升了142.86%,情感可解释任务提升了77.12%,视频语义理解任务提升了50%,各团队的技术方案有力地推动了相关任务的技术探索。在论坛的评测报告环节,四大任务的冠军团队对各自的参赛方案做了分享。
在段落检索任务中,来自中国科学技术大学的“young的团队”提出了一种基于弱监督数据预训练的开放问答段落检索方法,该方法可以有效提升检索准确率。在知识对话赛题中,来自腾讯的“拿件T恤就溜”团队,设计了一个基于实时知识搜索API的知识对话系统,实验表明该方案可以显著提升对话整体的连贯性和吸引力。在情感可解释任务中,阿里巴巴的“Ali_农民工团队” 提出了一个基于通用信息抽取统一框架 UIE的情感可解释分析方法,该方法根据情感可解释任务的特点,使用few-shot、文本聚类等方法,提高了模型的合理性、忠诚性。在视频语义理解任务中,来自商汤科技&香港科技大学的“商汤NLP×LaVi的团队”针对分类标签预测任务和语义标签预测任务,分别设计了对应方案,提出了基于多模态学习的视频语义理解模型,并通过数据增强、数据加权和多模型集成进一步提升方案性能,最终脱颖而出。
针对此次竞赛,百度自然语言处理部主任架构师刘璟进行了总结,他表示:“四大任务的优胜方案相对基线均大幅提升。各优胜队伍均基于预训练模型进行了一系列的创新,如采用prompting技术、面向任务的预训练等,有效地推动了技术的进步。目前来看,知识融合、可信学习、跨模态等技术在应用落地中还存在很多挑战,未来需要更大地突破。”
值得一提的是,本次竞赛数据集均来自于千言中文开源数据集项目。千言是面向自然语言处理的中文开源数据共建项目,由中国计算机学会、中国中文信息学会和百度联合发起,目前已有近20家单位的数据集作者参与共建,已有覆盖文本生成、情感分析、阅读理解等15个任务方向的近60个中文NLP开源数据集入驻。

2022语言与智能竞赛发布了首个来自搜索引擎的大规模中文段落检索数据集DuReader_retrieval、首个服务信息增强对话数据集DuSinc、首个细粒度中文情感可解释评测数据集DuExplain、视频语义理解数据集 DuVideoTag。赛后,开发者可继续在千言数据集官网下载使用以上数据集,并参与相应的榜单评测,不断提升技术水平,实现创新发展。
语言是人类信息传递最重要的媒介,近年来自然语言处理领域获得了产学研各界的持续关注。语言与智能技术竞赛将继续提供面向真实应用场景的数据集和富有挑战性的任务设定,引领学术研究面向真实应用,提升语言理解与人机交互智能水平,为推动语言与智能领域技术发展和应用贡献力量。




