
ChatGPT带火了智算中心的概念,然而从国际的角度来讲,并没有专门定义什么是智算中心(AI DC),但在中国被定义为一个新的品类。
那么到底什么是智算中心呢?在数据中心中,为了能够完成大模型的训练和推理,引入了GPU服务器部署,这样的数据中心我们就称之为智算中心。所以说到底,智算中心是数据中心中的一类。
智算中心有三大要素,即:算力、网络和数据,这三者相互关联,不可分割。我们以网络为例,由于引入了GPU的并行运算,算力水平大大提升,就好像马路上并行行驶的汽车增加了,那么车道数也要增加一样,因此网络带宽的能力需要急速提升。
智算中心提速,网络水平跟上了吗?
为什么这里讲“急剧提升”,给大家讲讲实际情况。前几年,当我们提到400G、800G觉得好像很遥远,因为大家常用的还是10G、25G、50G网络。但是,GPU并行计算一下子把网络推到了400G以上。
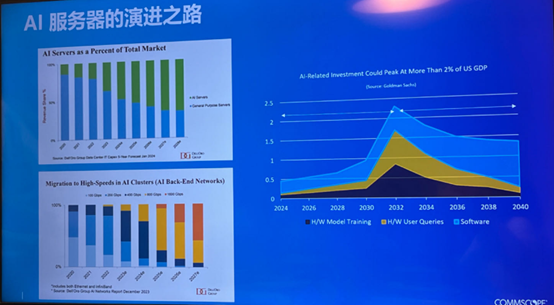
图 | 2027-2028年前后,数据中心中GPU服务器的数量将超过CPU服务器的数量,来源:康普,与非网摄制
与此同时,近年来,在数据中心中,GPU服务器的占比越来越高。根据Dell’Oro Group的数据显示,预计在3-5年后,即2027-2028年前后,GPU服务器的数量将超过CPU服务器的数量。
如果一台智算设备内部有8个GPU卡,它内部通讯要达到900G,那么外部通信用的InfiniBand网络或以太网也需要跟上步伐,提升到400G,甚至800G。换言之,随着智算的快速推进,400G以上网络的占比将占主导地位,包括400G、800G和1.6T。
此外,我们看到,GPU算力正在以每年翻两倍的速度增长,10年就是1000倍,那就预示着,网络也需要10年提升1000倍,所以网路的发展已经滞后于算力。
中国为何选择“原生非无损网络”的以太网?
前面提到,CPU、GPU之间的内部通信采用的是PCIe、NVLink接口标准,而外部传输是用的InfiniBand和以太网接口标准,在智算中心中我们常称它们为“IB”和“ROCE”。那么,这两种标准间有什么区别呢?哪种标准更适合中国智算中心市场?
IB技术来自于Mellanox,是一种专为高性能计算(HPC)和数据中心环境设计的高速通信协议,以其低延迟和高吞吐量而闻名,后来Mellanox被英伟达收购了,IB技术几乎成为了英伟达生态专属。
相比无损网络IB,ROCE属于后起之秀,它实际上是一种借助以太网来支持远程直接内存访问(RDMA)的机制。由于从诞生的机理来讲,以太网就不是一个专用网络,而是一个尽力而为的网络,所以很多人会质疑ROCE能否追上IB。

图 | 康普企业网络大中华区技术总监吴健,来源:康普
对此,康普企业网络大中华区技术总监吴健表示:“IB在整个智算里面的效率、稳定性要比以太网好,同时以太网很难做到无损也不假,但现在的以太网从协议层面、硬件层面,以及一些技术点上做了很多优化,几乎可以做到无损。我认为ROCE的速率发展跟IB的速率发展差不多,都会快速地进入到800G、1.6T时代。”
此外,吴健认为:“当前IB跟ROCE是共存的状态,这是因为英伟达主导了整个AI,而英伟达提倡用IB,但是在中国,以太网取代IB是势在必行。”
“在中国,没有一个纯粹的AI数据中心,GPU集群往往是数据中心中的一部分,或者属于Cloud中的一部分,如果要跟Cloud去做融合,那就一定会用到以太网,因为在融合方面以太网肯定比IB要好。”吴健解释道。
网络带宽大幅提升,倒逼光互联方案发展
智算中心中的网络带宽急需提升,为了提高端口密度并减少端口所需的空间 ,同时降低系统功耗,可以容纳多根光纤的MPO(Multi-fiber Push On)光纤连接器被大量使用,比如MPO16、MPO8;同时CPO(Co-Package)共封装光学连接方案将在800G和1.6T时代占据主流。
目前来看,可能IB的情况基本是以MPO8为主,ROCE以太以MPO16为主,它采用的收发器是有区别的,但是收发器出来之后光纤连接对于布线设计来讲是一样的。
关于光互联方案,当前,数据中心光互联的方案主要有三种:
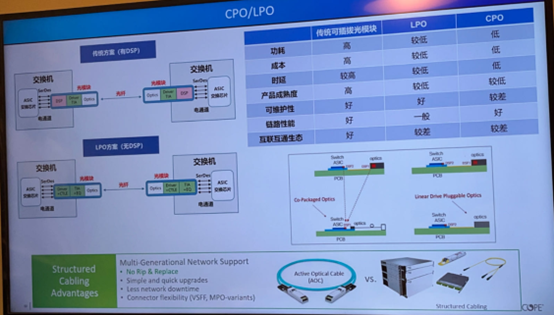
图 | 三种光互联方案的对比,来源:康普,与非网摄制
第一种是传统的光模块连接方案,其中可插拔的光模块就是光引擎,光纤插在光模块上,通过SerDes通道将信号传送至网络交换芯片。这种方案中采用了DSP芯片对高速信号进行信号处理,来降低误码率,所以在链路性能、灵活性、可维护性和不同厂商间的互操作性方面表现良好,但DSP的功耗较大,以400G光模块为例,当前市场上采用7nm工艺的DSP芯片功耗通常要跑到4W,占整个光模块功耗的50%左右,而光模块的功耗大约占交换机整机功耗的40%以上,所以在低功耗方面表现不佳。此外,由于交换芯片和光引擎是分开布局的,所以在信号延迟表现方面也一般。
第二种是LPO线性驱动可插拔光模块连接方案,顾名思义,该方案采用了线性直驱技术,去除了传统光模块的DSP/CDR芯片,将系统功耗和延时做了优化,同时成本也相应降低,但也正因为做了简化处理,所以在系统误码率和传输距离方面有所牺牲。不过该方案依旧保留了传统光模块方案的可热插拔的特性,所以在后期维护方面存在优势,不至于单个元件损坏,要拆机才能维修。
第三种是CPO共封装光学连接方案,在这种方案中,最大的改动就是将交换芯片和光引擎进行了合封,不再采用可插拔光模块的形式,带来的好处是电信号在光引擎和交换芯片之间的链路缩短了,传输速率会更快,功耗更低,效率更高,且在尺寸方面也会缩小不少。有行业数据显示,采用CPO的方案,相比于光模块的方案,功耗可以降低50%,且能满足高速、高密度互联的传输场景,比如未来的智算中心。
吴健认为:“CPO方案将在800G和1.6T时代开始量产出货。LPO作为这种方案还会存在一段时间,至于何时CPO将在智算中心中全面取代LPO,取决于光模块厂商的‘挣扎’。不过,当光互联的方式演进到CPO(Co-Package,共封装模式)时,没有了AOC(Active Optic Cable),就会出现标准布线系统,光纤直接和设备相连,更利好布线设计和部署。”
智算中心部署仍面临多重挑战,如何破局?
“虽然布线只是智算中心成本支出中的很小部分,但是其重要性不可忽视,我们不能让布线成为智算中心这个大工程中的最大短板。” 康普企业网络大中华区总经理兼副总裁陈岚如是说。

图 | 康普企业网络大中华区总经理兼副总裁陈岚
这道出了布线的重要性,实际也是如此。举个例子,同样是400G、800G、1.6T也会有很多选择,如下图所示。
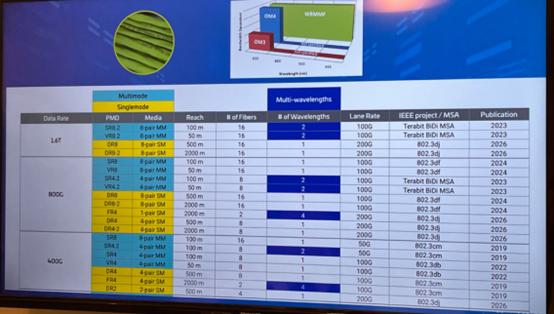
图 | 网络带宽部署选择方案,来源:康普,与非网摄制
更何况,智算中心还面临AOC等有源跳线施工难、机房环境洁净度差、线缆拉力问题、光纤线槽与物理保护问题、接头性能与光线品质问题、线缆外皮等级问题等挑战。
关于AOC等有源跳线施工难挑战,吴健透露:“当前,不论是在传统的光模块连接方案还是在LPO线性驱动可插拔光模块连接方案部署中,AOC的使用都遇到了很多麻烦,这种形态的产品在施工的时候特别容易断,所以现在基本不会用它,而是采用标准模块、标准布线的方式。”这也从侧面印证了AOC将退出时代舞台,同时在智算中心应用中,CPO方案下的标准布线将成为未来主流。
所以,在智算中心建设过程中,选择一家综合实力强,产品有保障的网络架构与布线设计公司来辅助部署,就会事半功倍。
值得一提的是,康普在智算中心布线领域,有着较强的前瞻性,在两年前就推出了模块化和超低损耗的端到端高速光纤平台Propel™,来满足服务器不同链路中不同网络带宽和连接方案的布线所需。
关于品质保障这一块,陈岚强调:“康普的光纤产品有25年质保期,并且针对25年质保期内的应用和性能提供了一份白皮书,由于在设计时就留了性能余量,因此经得起时间考验,客户一旦测试出不达白皮书中所述的标准,康普会免费更换升级。”
写在最后
高盛的报告预测,智算中心的硬件发展峰值时间将出现在2032-2033年间,峰值过后就是后期的软件、算法、数据这方面的事情,这意味着未来的8年里,智算中心硬件将保持快速增长。
而对于中国市场来讲,这几年对智算中心的投入很多源于“热钱”,还缺乏长期的规划和部署,所以中国的智算中心/数据中心的生命周期大约在4年左右,远低于国外发达国家产业化布局下的15-20年,这将给整个AI产业发展带来困扰。而其中影响智算中心/数据中心生命周期的点,涵盖机柜电源、布线、网络等。
此外,当前大家把更多的关注放在GPU等核心芯片上,事实上真正国产化低的是高速网卡,目前基本都是外购英伟达等企业的,所以这也是接下来AI产业要克服的重点。




